Fragmentation and inconsistency
The same entity appears differently across systems: names vary, identifiers are missing, formats diverge, documents are incomplete. Mapping has to tolerate ambiguity and improve over time.
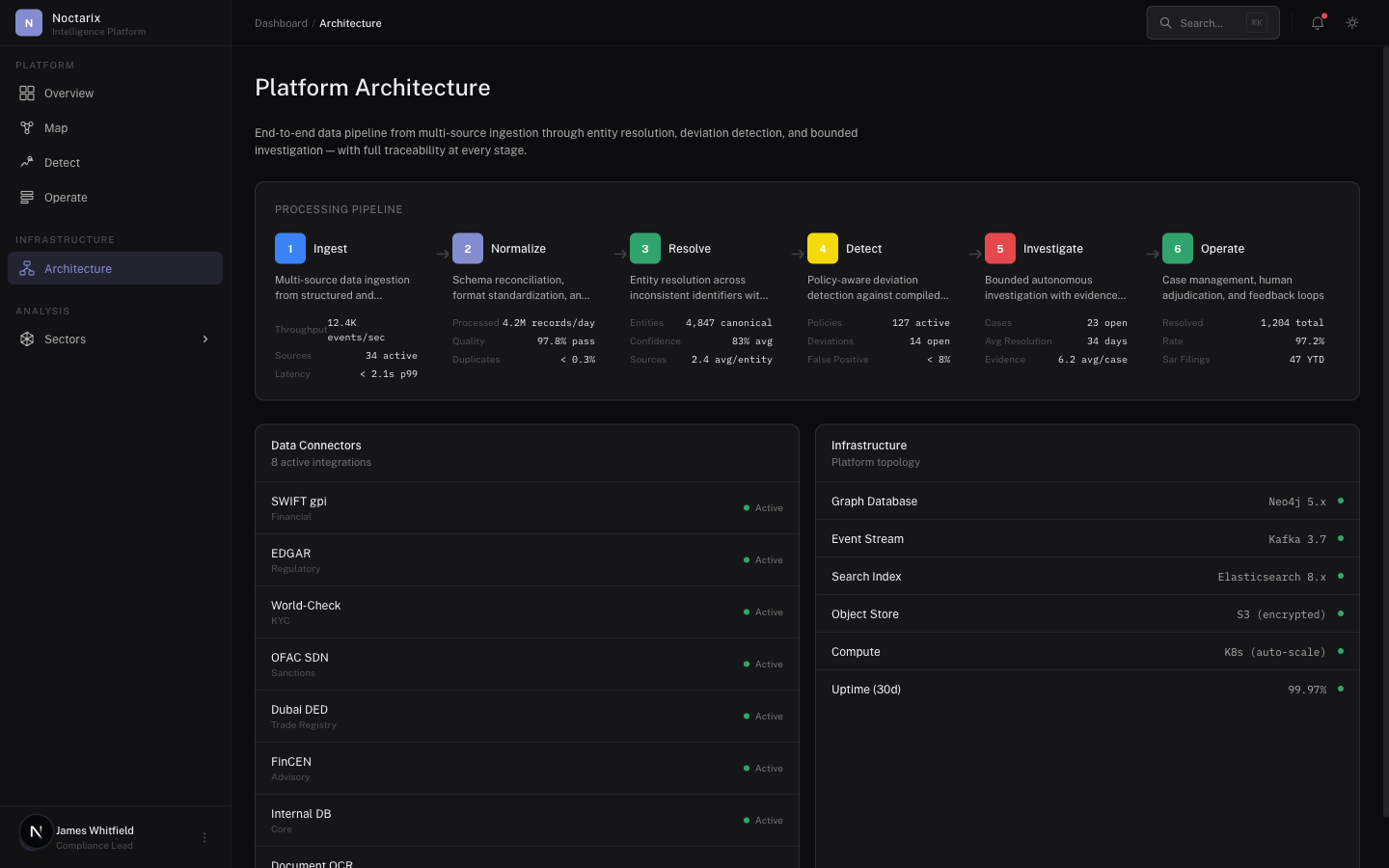
A coordination layer that converts fragmented institutional data into timely, accountable action. Not a BI stack. Not a chat interface. A closed operational loop.
The Noctarix platform is a closed operational loop: ingest fragmented data, resolve entities into a live graph, compile policies into executable process models, detect deviations, investigate with evidence chains, and feed outcomes back into the system. Not a BI stack. Not a chat interface.
The same entity appears differently across systems: names vary, identifiers are missing, formats diverge, documents are incomplete. Mapping has to tolerate ambiguity and improve over time.
Decisions require justification. A system that cannot produce an evidence chain doesn't survive the first audit.
Institutional systems aren't upgraded by mandate alone. Phased deployment, controlled scope, measurable outcomes.
Access control, auditability, data residency, and policy constraints aren't optional features. They're table stakes.
Data enters from multiple sources (structured + unstructured)
Entities are resolved into a live graph with provenance
Normative process expectations compiled from policies and SOPs
Deviations and anomalies generate prioritized cases
Investigations assemble evidence packages
Humans adjudicate and decide
Outcomes feed back into the graph and detection thresholds
The system improves operationally through this loop — without relying on vague claims of “self-learning.”
Noctarix ingests from the institutional landscape: relational databases, transaction streams, document repositories, ticketing systems, field logs, PDFs, scans, and semi-structured forms.
Operational data rarely arrives clean. Schema drift, inconsistent fields, partial records — handled through transformation pipelines designed for continuous change, not one-time migration.
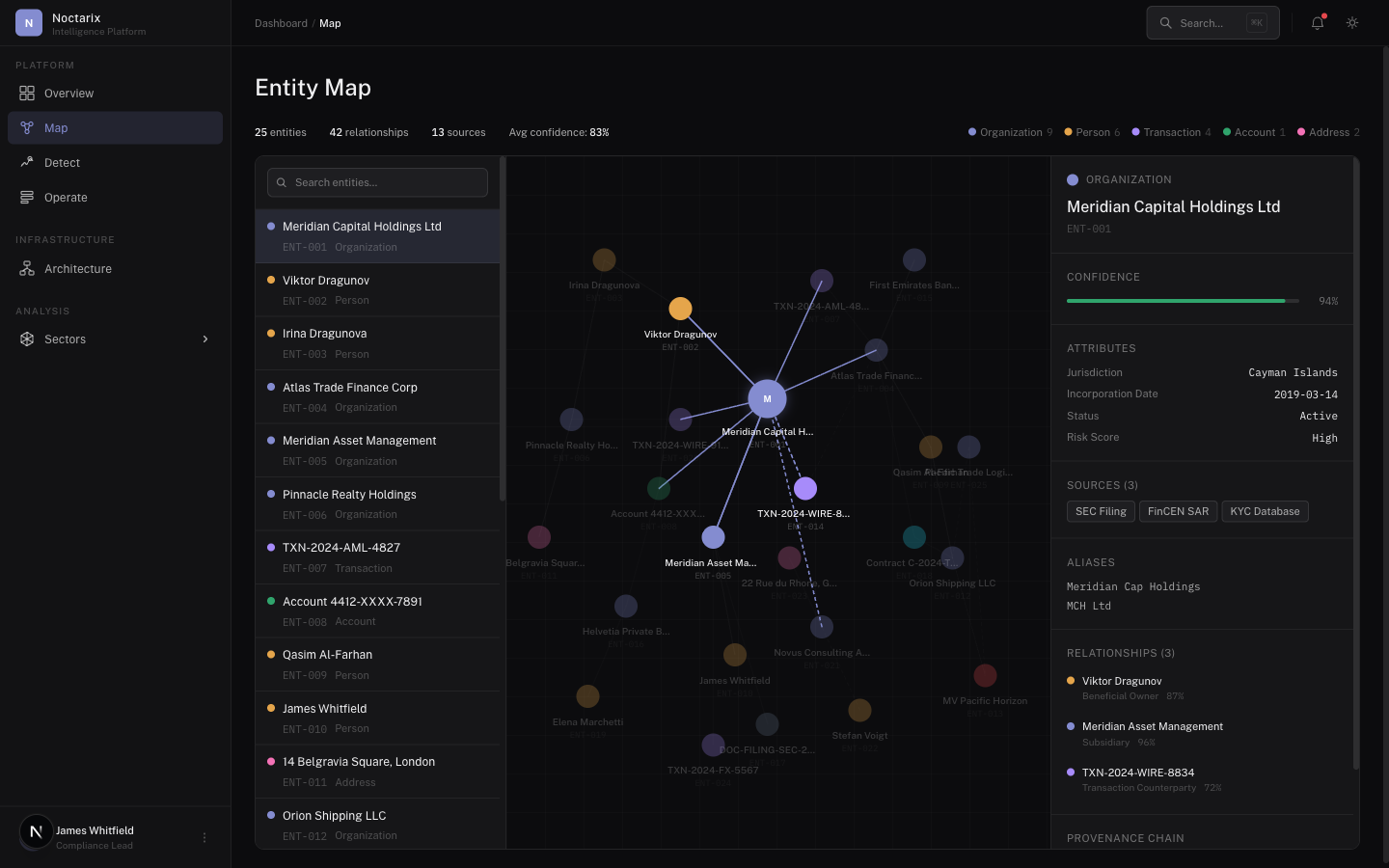
This is the core engineering challenge. Link records into canonical entities using deterministic rules and probabilistic resolution. Preserve: confidence scores per link, competing hypotheses when ambiguity exists, provenance back to raw sources, reversible transformations.
Entities and relationships stored as a queryable graph: traversal queries for investigations, incremental updates from new data, time-aware analysis, entity-level views for operators.
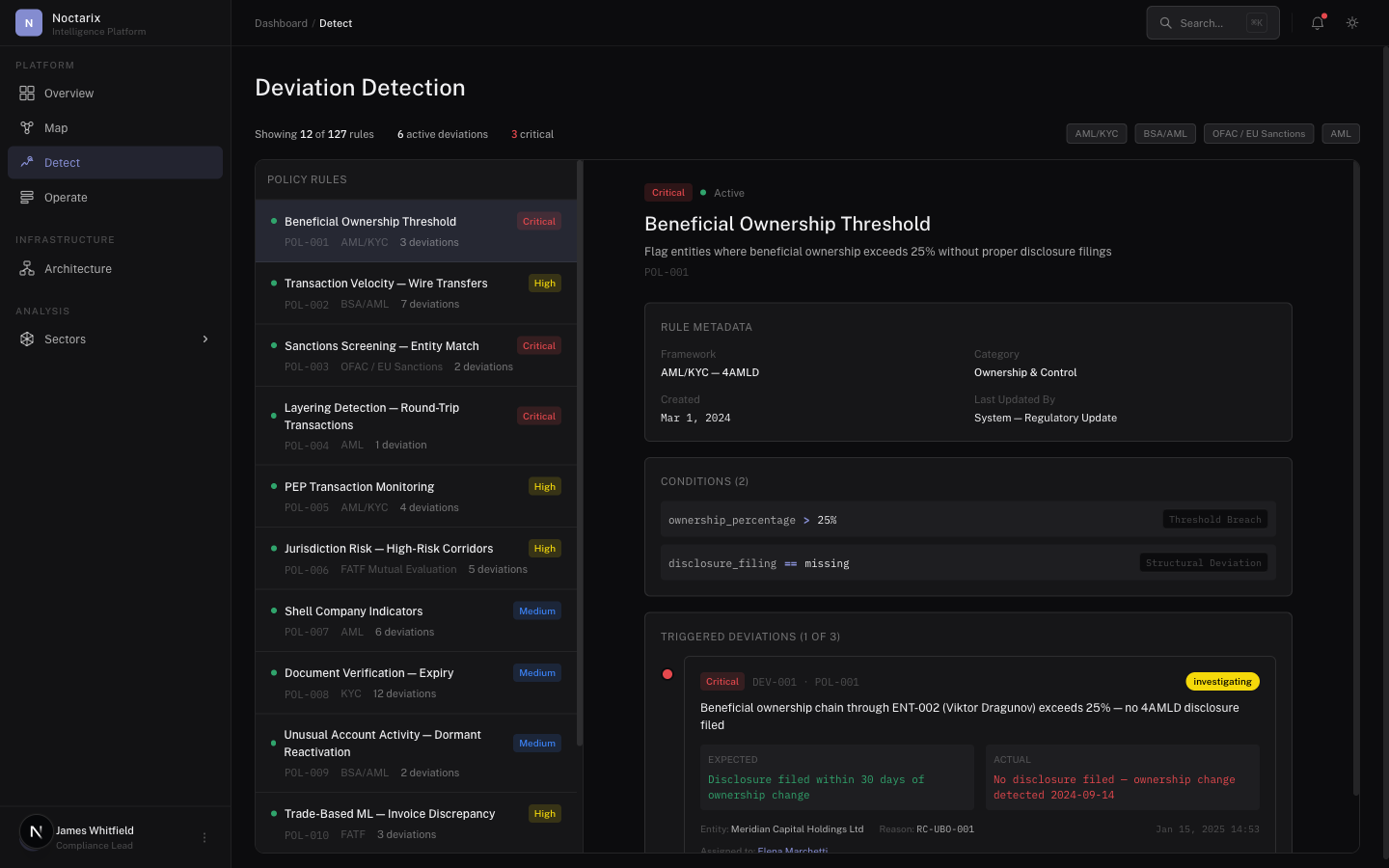
Read regulatory requirements, SOPs, compliance frameworks. Extract expected steps and checks, constraints and thresholds, approval boundaries, required documents. Compile into executable process graphs — versioned, reviewable models of how things should work.
Detection is not only "weird behavior." It's divergence: a step missing, an approval absent, an entity relationship inconsistent with policy, a multi-source contradiction. Outputs are structured cases with rationale. Not noise.
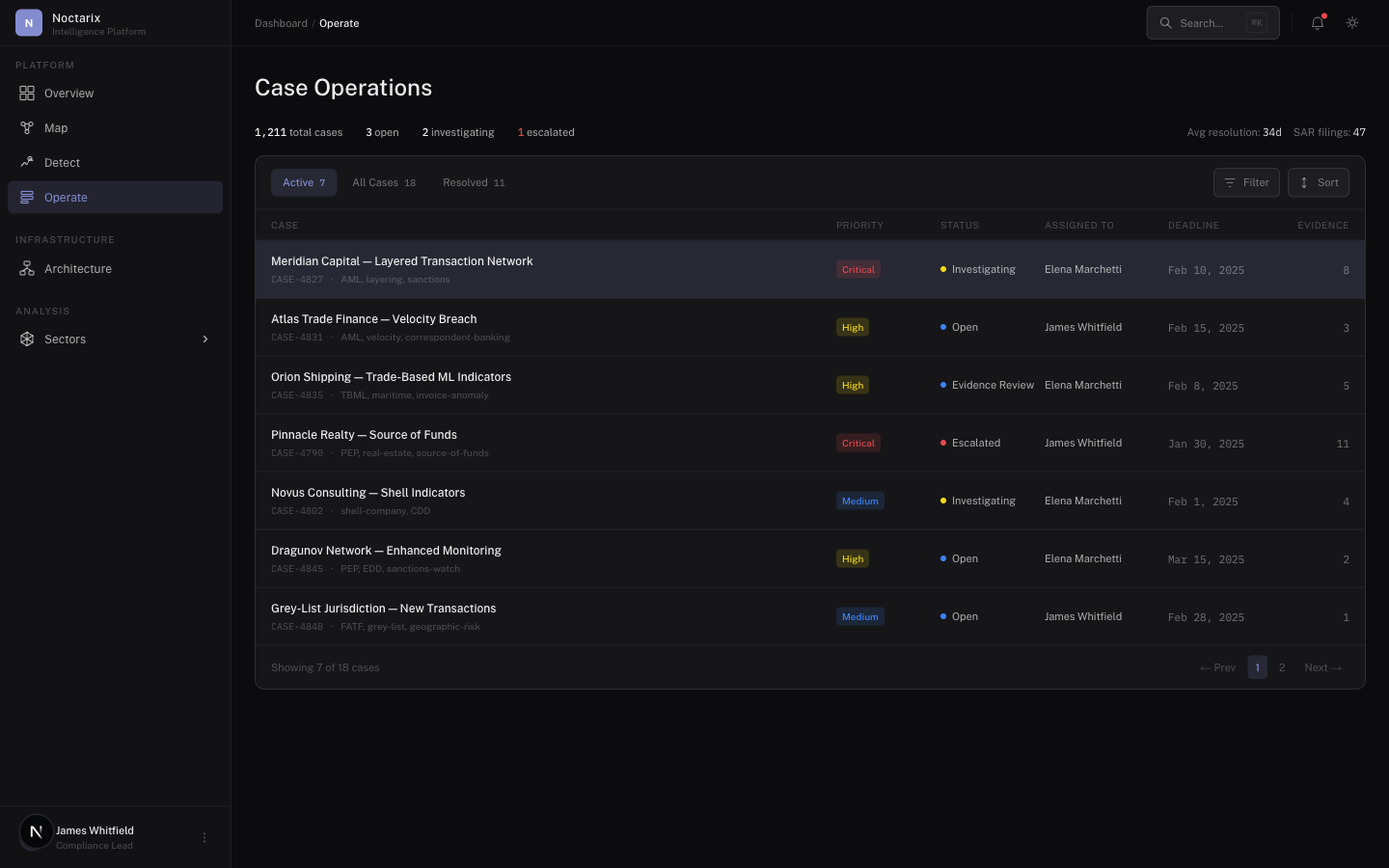
When a case is created, execute investigation playbooks: traverse entity neighborhoods, fetch supporting documents, reconcile contradictions, compute risk factors, assemble a traceable evidence package. Controlled execution with trace — not open-ended autonomy.
Investigations surface through a casework interface: case summary and rationale, evidence timeline, linked entities, recommended next actions, escalation paths, disposition and closure.
Every output is traceable: which sources were consulted, what transformations applied, what the system inferred, what the human decided, what policy checks were evaluated. Required for institutional credibility.
No requirement to centralize all systems into a new data lake upfront
No opaque model with autonomous authority over decisions
No permanent lock-in through proprietary schemas without export
No "rip and replace" deployments